
What I Learned Scraping Data for my Capstone
After 12 intense weeks of learning, I graduate from BrainStation’s Data Science bootcamp this week.
My capstone project is “Predicting Coffee Ratings from Expert Reviews”. You can check out the full project in my github.
Picking a Topic & Scraping the Data
In selecting a topic, I had a few parameters in mind. I wanted to:
- Work on data that was relatively unexplored
- Select a topic that was easy to understand so that I could focus on the technical skills instead of understanding the topic
In addition, a prior classmate scraped some data for a project we worked on together. I was intrigued by the idea and wanted to learn how to do this myself.
Separately, I came across some projects looking at coffee ratings. Many of them seemed extensively explored, and I wasn’t happy with the quality of the datasets. But I do enjoy coffee and the topic fit my “easy to understand” criteria. So, I decided to scrape my own data from CoffeeReview.com.
What Did I learn?
- Beautiful Soup is an awesome library
- Scraping messy data was pretty straight forward, but it was much more challenging to scrape the specific data I wanted
- Scraping can be time consuming
- Scraping in smaller pieces reduced wasted time trouble-shooting errors
- A little help can go a long way
My first attempt at scraping data was challenging and exciting. It was surprisingly easy to scrape data but it was in a very messy format. I wanted to be more precise to make cleaning easier later. I spent a couple days banging my against the wall, and then asked a web developer for some help understanding the html text. Once I had a baseline for what I was looking for, I was on a roll. I could hone in on exactly what I needed and it was so satisfying.
Another challenge was that scraping was time consuming. At first I tried to scrape a lot at once, only to have errors appear hours later and have to start over. It turned out that some of the older webpages had a different format that more recent ones, so I changed tactics. I created two ‘scraper’ functions. One requested more details and the other fewer to accommodate the content changes. I then ran the scraper in smaller chunks. I also added an exception so that the scraper would continue if it got an index error (meaning some of the data I requsted was missing).
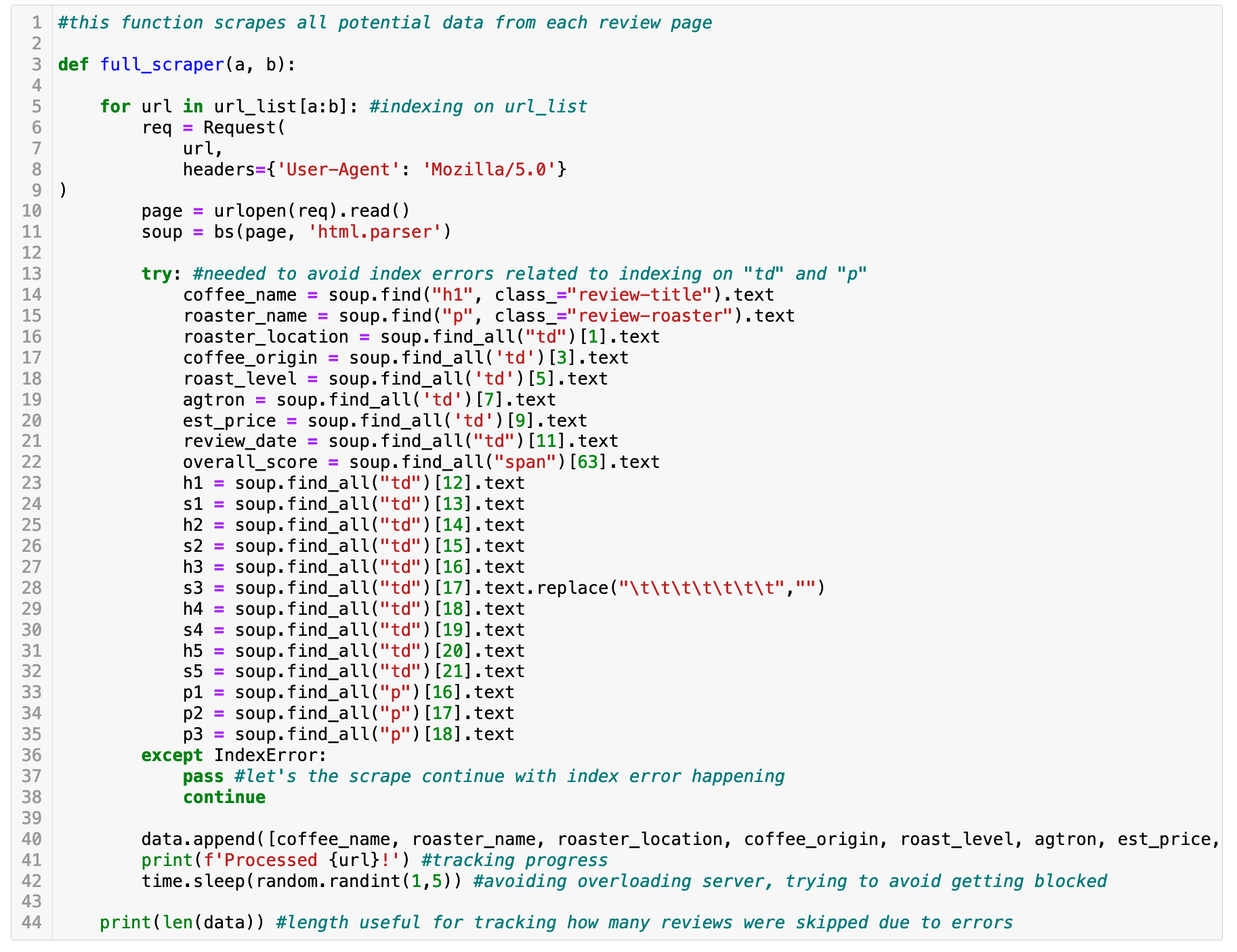
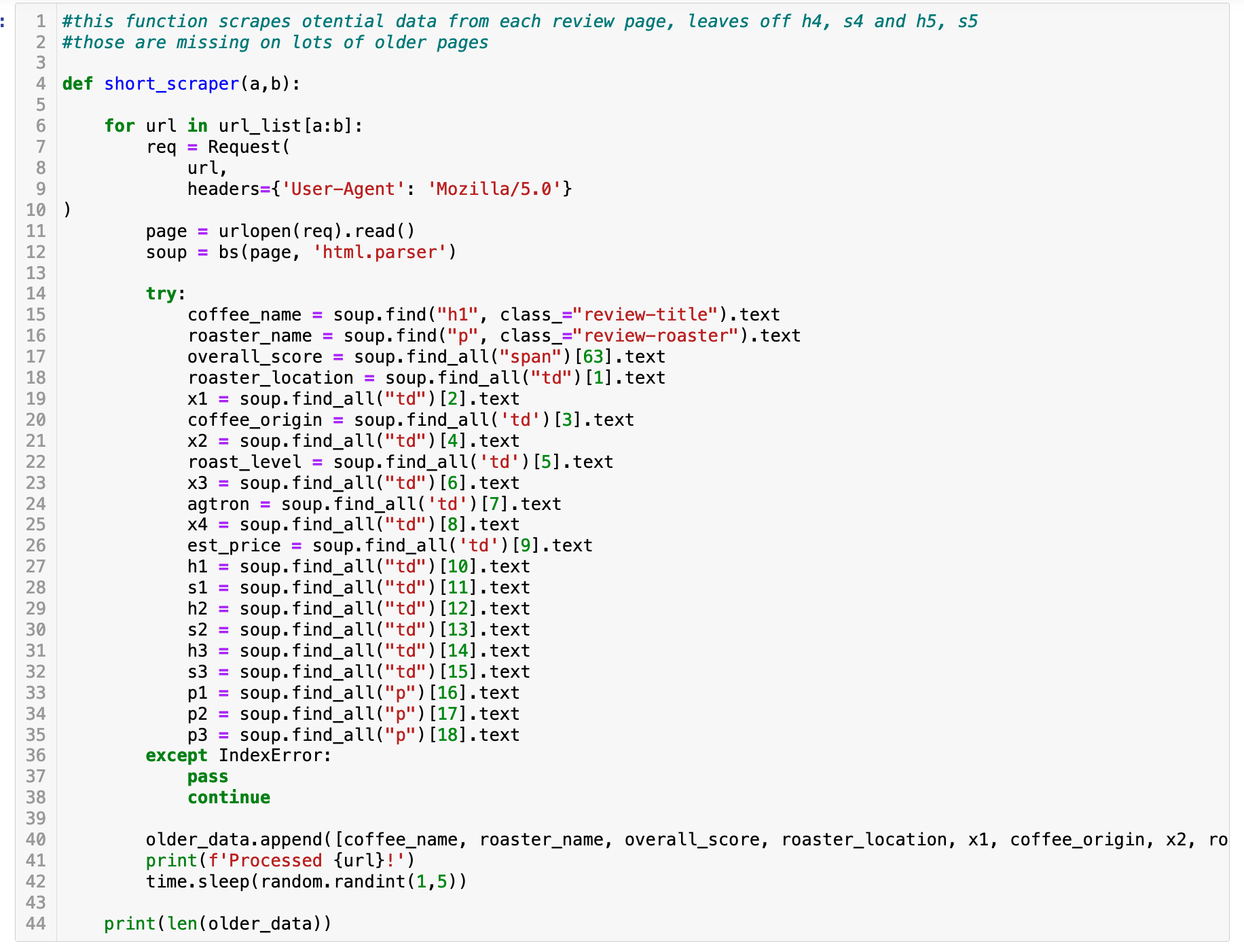
In the end, I was able to scrape ~6,500 reviews, which became my dataset for the project. I’m glad I took on the challenge of scraping my own data and it was fun to work on a unique dataset for the project.